Gradients without Backpropagation
arxiv
First written: Mar/27/2022, 08:38:20
Summary
This paper derives a methodology for computing gradients during the forward pass of a neural network, as opposed to "backpropagation", which conventionally requires a second, reverse pass of the network to compute gradients for optimization.
Introduction
- Differentiability is one of the main reasons for success in modern machine learning; frameworks support model optimization with efficient automatic differentiation (AD).
- Neural networks typically present a special two-phase algorithm for differentiation, whereby scalar valued objectives are differentiated against many parameters in an efficient manner with "reverse mode" AD.
- The umbrella of AD algorithms include both reverse (the conventional type) and forward modes, with the latter requiring only a single evaluation of a function; the caveat is that the two modes evaluate different quantities: for a function that maps dimensions to ,
The forward mode evaluates a Jacobi-vector product:
The reverse evaluates a vector-Jacobi product:
In the specific case of scalar valued objective functions, where , forward mode gives the vector directional derivative whereas the reverse mode gives what we actually want, which is the full gradient .
Reverse-mode AD
Given a neural network function parameterized by that maps dimensions to , the typical reverse mode AD evaluates the vector-Jacobi product , where is the full Jacobian of all partial derivatives of evaluated at .
For the case where , reverse mode AD yields the partial derivatives of for inputs, such that , i.e. a vector of gradients with respect to parameters .
Forward-mode AD
Given a neural network function parameterized by that maps dimensions to , the forward mode AD evaluates the Jacobi-vector product , where is a matrix comprising all partial derivatives of evaluated at , with a vector of perturbations/tangents.
For the case where , i.e. maps dimensions into a scalar, we evaluate , which is the projection of gradients along the perturbations . Because we're evaluating projections of the gradient, to evaluate the full Jacobian matrix as needed for optimization, we could use forward mode times in a column vector basis, which would yield columns of .
The challenge therefore is to find a method that evaluates forward-mode AD for parameter gradients without needing to it times.
Performance
According to 1, both modes of AD involves a constant multiple of the time required to evaluate .
The typical reverse mode needs to perform a backward pass, and needs to use some memory mechanism to track all forward operations, which are used in the backward mode evaluation. The forward mode naturally does not require this.
Factorizing the cost of AD as primitive operations, everything boils down to memory access, additions, multiplications, and nonlinearities. Because AD takes a constant multiple of runtime, the authors conveniently express forward- and reverse-mode AD time as and , with on the order of 1–3, and on the order of 5–10 with the caveat that this depends heavily on the nature of the program/application.2
Methodology
To make forward-mode AD viable, we need a trick to expose from ; i.e. project the directional vector out. In order to do so, the steps taken by the authors are:
- Sample random perturbation vector ,
- With forward-mode AD, obtain and
- Multiply with vector to obtain gradient
The chief proofs of this paper is to show that the forward gradient is an unbiased estimator of the true partial derivative by the expectation value:
and for the case when is expressed in terms of , i.e. , we reduce the equation above to .
Concretely, they present a "forward-mode" gradient descent algorithm for iterations :
- Sample perturbations from a multivariate Gaussian with diagonal covariance;
- Compute the Jacobi-vector product () and function ()
- Compute gradients as vector-scalar product
- Perform parameter updates as per usual ()
Results
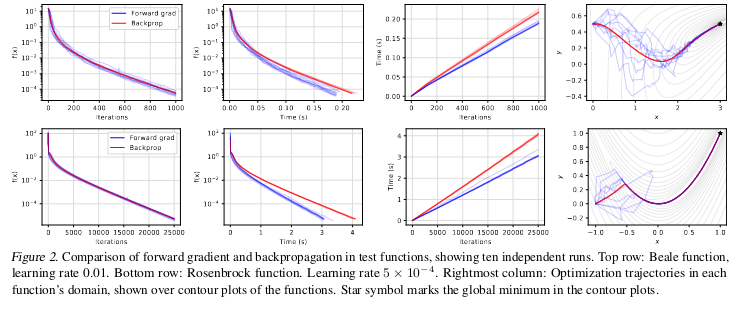
On toy model functions (e.g. Beale and Rosenbrock), the results suggest that forward grad is marginally faster than backprop, albeit with some interesting optimization trajectories. Both end up in the global minima, although forward grad shows some pretty crazy ways to get there (blue traces, rightmost panel for each row)
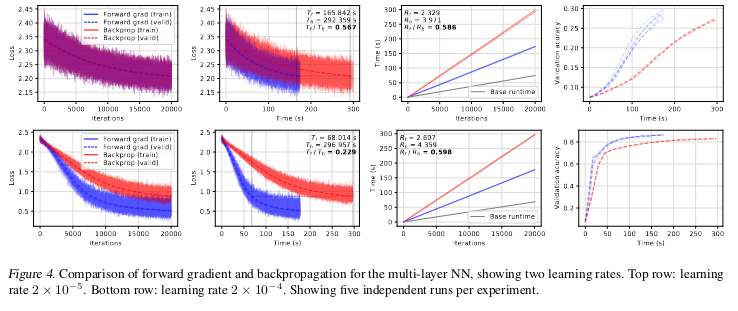
Stepping up in function complexity, the authors look at MNIST classification with MLPs. The key results here are that empirical mean runtimes for both forward- and reverse-mode AD are R_f = 2.46 and $R_b = 4.17 respectively, showing a non-trivial speedup for the former. The other potential benefit owing to the stochastic optimization trajectories is you basically have an annealing effect, whereby the model implicitly explores more regions the loss surface and reaches convergence quicker.
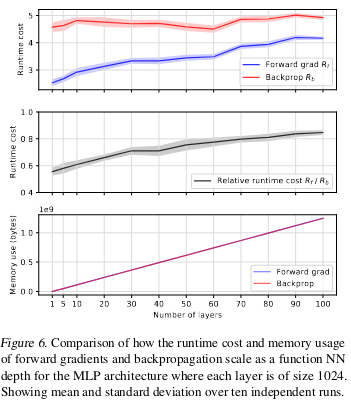
That said, the last figure seems to dimminish the allures of forward-mode AD: at the limit of a large number of layers/parameters, the runtime improvement of forward-mode AD diminishes. Another aspect I don't understand is why the memory usage is also effectively the same for both forward- and reverse-mode.
Further reading
- Griewank, A. and Walther, A. Evaluating Derivatives: Principles and Techniques of Algorithmic Differentiation. SIAM, 2008.↩
- Hasco ̈ et, L. Adjoints by automatic differentiation. Advanced Data Assimilation for Geosciences: Lecture Notes of the Les Houches School of Physics: Special Issue, June 2012, (2012):349, 2014.↩