scalable-uncertainties-from-deep-ensembles
arxiv
First written: Aug/20/2021, 09:32:40
Summary
- While [[neural networks]] are good at a wide range of tasks, they aren't good at knowing when and what they don't know.
- Part of the problem with this is that there is no ground truth for uncertainty; not something that can be easily testable. Same problem associated with quantifying #generalization since the data we need is by definition not available to us.
- This paper looks at using two ways to measure uncertainty from neural networks: [[calibration]] and [[domain shift]] or "out-of-distribution examples".
- Interpretation of [[dropout]] uncertainties by Gal and Ghahramani as both [[MCMC]] sampling, as well as "creation" of [[ensembles]] of neural networks.
- Fundamentally, the question is whether or not ensembles of neural networks are any good at providing good uncertainty estimates.
[[bayesian model averaging]] assumes that the true model lies within the hypothesis class of the prior, and performs soft model selection to find the single best model within the hypothesis class.
...ensembles can be expected to be better when the true model does not lie within the hypothesis class.
- A deep ensemble is supposed to be easier to implement and train than [[bayesian-neural-networks]], either variational or MCMC.
Calibration
- This figure shows the performance of the approach w.r.t. a simple 1D regression task, where
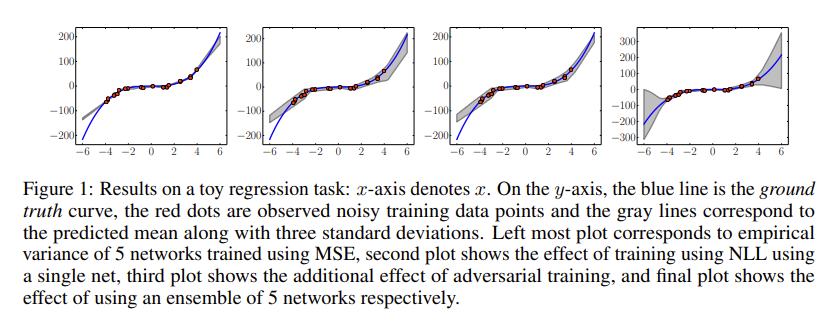
- First panel is empirical variance. Probably not much because each NN converges to the same weights?
- Second panel is training NLL using a single NN, third smooths the process with adversarial training.
- Final panel combines NLL + AT with five NNs.
- Other comparison made is on a few tabular datasets; deep ensembles typically have larger RMSE but better NLL.
Domain shift
- Test predictions on data from unseen classes: uncertainties should be proportional to distance from training data.
- Model is trained on a standard [[MNIST]] train/test split, however an additional testing class of [[NotMNIST]].
We do not have access to the true conditional probabilities, but we expect the predictions to be closer to uniform on unseen classes compared to the known classes where the predictive probabilities should concentrate on the true targets
- The left panel shows how the distribution in [[entropy]] is much broader/uniform for the ensemble + AT case, compared to the dropout uncertainties which are also much more discrete.
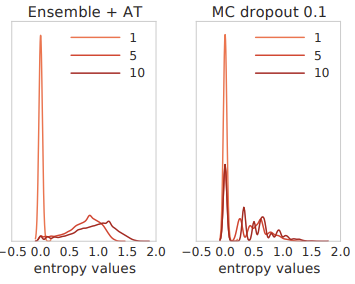
- Define a "confidence" value defined as the highest probability of a class. It shouldn't always be one for unseen examples.
Strategy
Given the input features , we use a neural network to model the probabilistic predictive distribution over the labels, where are the parameters of the NN.
- Three steps:
- Use a proper [[scoring rule]]; where can be [[maximum likelihood]]/[[mean squared error]]/[[softmax]]. MSE is also known as the [[Brier score]].
- [[Adversarial training]] to smooth the predictive distribution
- Train an ensemble lol

Regression
- Typical regression NN will minimize MSE, i.e. the output corresponds to the regression mean. Here, the authors suggest to output two values: the predicted mean and variance. The variance is done via where is a small positive number of numerical stability.
- The [[negative log-likelihood]] criterion used:
Julia implementation:
begin
function nll(mu, var, y)
return log(var^2) / 2 + (y - mu)^2 / (2 * var^2) + eps(Float32)
end
endAdversarial training
Basically use conventional [[fast gradient sign method]], or [[virtual adversarial training]].
Ensemble training
- Choice between [[decision trees]] or [[boosting]]; the authors chose the former because they are much better for distributed training.
- There is an extensive discussion into decorrelation of trees with [[bootstrapping]]; the authors instead just use random initialization of the parameters, and shuffle the training data points for each "tree" in practice.
- Apparently [[stochastic-multiple-choice-learning]] helps with de-correlating the NN "trees".
- Ensemble as a uniformly-weighted [[mixture model]]
- For classification, averaging the predicted probabilities
- For regression, Gaussian mixture, with a mixture mean and variance
A naive Julia implementation:
begin
"""Reduce the predictions from each tree into an ensemble
mean and variance. Assumes `means` and `vars` are a list
of vectors.
"""
function reduce_ensemble(means, vars)
means = reduce(hcat, means)
ensemble_mean = mean(means, dims=2)
vars = reduce(hcat, vars)
ensemble_var = mean(means.^2 .+ vars.^2, dims=2) .- ensemble_mean.^2
return ensemble_mean, ensemble_var
end
"""Given a struct `ensemble`, and inputs `x`, we loop over
each tree in the ensemble/forest (also assuming tree is a functor)
and collect up all of the means/variances predicted by each tree.
We then bag the results.
"""
function predict(x, ensemble)
means, vars = [], []
for tree in ensemble.forest
mean, var = tree(x)
push!(means, mean)
push!(vars, var)
end
ensemble_mean, ensemble_var = reduce_ensemble(means, vars)
end
endComments
- Good for #distributed training; maybe a good use case for #intel-research.
- 5 NN's seem good enough for uncertainty estimation, but not sure how this really actually scales for real tasks.
- How does it really fit into a hypothesis testing context?
Implementation notes
I've implemented in terms of the toy regression problem, as well as in a an applied case. The uncertainties you get out are not necessarily as promising as shown in the Figure; either there's a degree of random seed cherry picking, or there are very selective scenarios (i.e. training dynamics) where you get such a pronounced predicted variance, particularly #aleatoric uncertainty. In the applications I've worked on, the ensemble variation is definitely significantly smaller.
That said, maybe I didn't implement it in the way that was originally intended; from slides I found for a DeepMind talk:

...it mentions the bagging is done at test time, but not for backprop? Not sure how you'd learn from NLL that way.
Need better ways to improve variability in the models; initialization, bootstrapping, or maybe something more sophisticated? Spawning dynamics perhaps