vicreg: Variance-invariance-covariance regularization for self-supervised learning
arxiv
First written: Sep/03/2021, 09:20:52
Summary
- Un/self-supervised learning of representations is difficult: embeddings can likely end up with highly correlated features1
- We also want to preserve the idea that similar inputs should result in similar encodings, with the most straightforward result being the same embedding regardless of inputs (i.e. a collapse). This also involves some clustering heuristic that might not be simple.
- Conventionally, good embeddings can be obtained through [[contrastive-learning]], forcing dissimilar inputs to have different embeddings, and vice versa
- Contrastive learning is expensive, however, because to do it well you have to find examples and counterexamples during training; e.g. [[triplet-loss]] variants.
- VICReg encodes three heuristics as a form of regularization: variance, invariance, and covariance
Useful embeddings
- The requirements typically are:
- Similar inputs -> similar embeddings (i.e. clustering)
- Dissimilar inputs -> dissimilar embeddings (i.e. contrast)
VIC regularization
...the architecture is completely symmetric and consists of an encoder that outputs the final representations, followed by a project that maps the representations into projections in a embedding space where the loss function will be computed.
- Projector gets rid of low-level information in the representations, and is only used for computing the loss (i.e. not used for actual tasks)
Notation
| Symbol | Meaning |
|---|---|
| , | Batch of embeddings, for either network |
| The representation used for tasks | |
| Batch size | |
| Embedding dimensionality | |
| Variance (regularization) | |
| Small scalar for stability |
Architecture
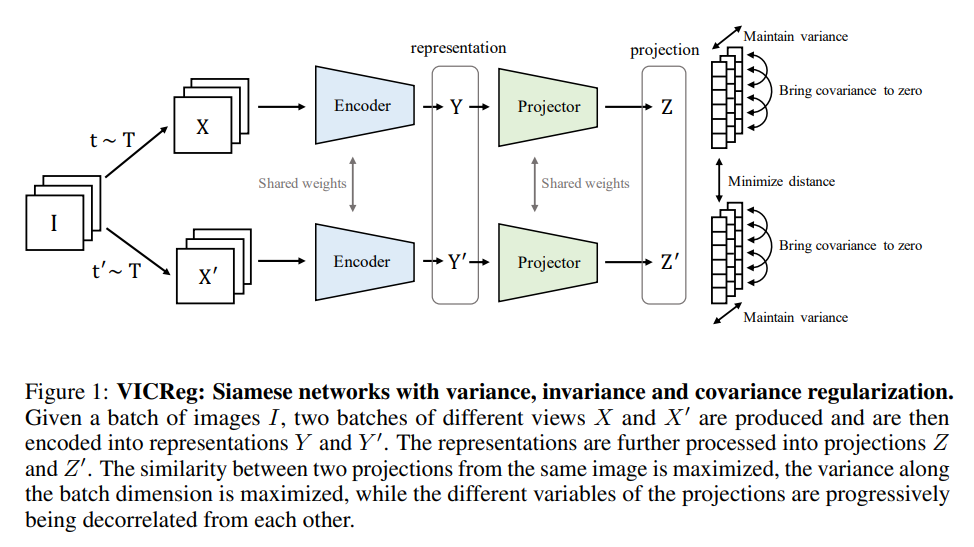
Variance
The variance regularization term is given by a [[hinge-loss]]:
where is a target value for the standard deviation (fixed to one for this paper)2, and is the variance estimator:
This forces the variance in a batch of embeddings to be along each dimension.
Covariance
The covariance of matrix is given as:
with being the mean embedding across a batch. The actual covariance loss term is taken as the squared off-diagonal coefficients of that scales with dimensionality :
So that we force the embeddings to learn unit Gaussians similar to the -regularization in [[variational autoencoder]].
Invariance
The invariance loss is given by:
i.e. the mean squared Euclidean distance between each network embedding pair.
- This encourages the model to learn the same upstream representation for nominally the same input.
The full loss
with hyperparameters , , and .
Comments
[variational autoencoder]: variational autoencoder "variational autoencoder"