Explaining the Chemical Inventory of Orion KL
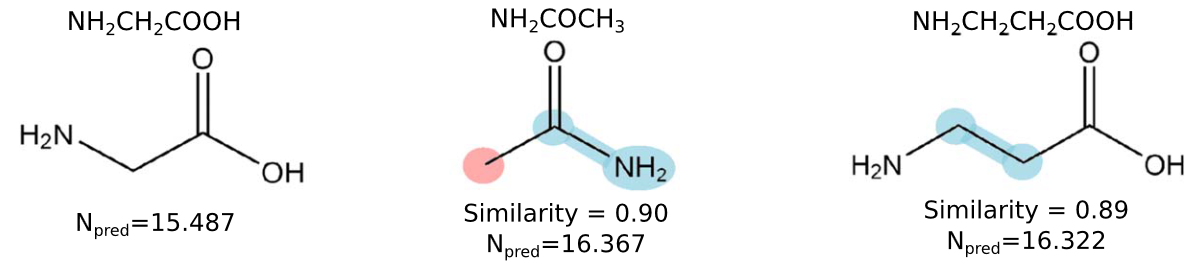
Extending the original TMC-1 work to a new, more complex source, we apply and develop a recurrent language model for embedding SELFIES strings of molecules. This latent space is used to train classical machine learning models, which combined with counterfactual explanations, significantly improves the degree of automation for (astro)chemical exploration.
In the first iteration of this work towards TMC-1, I developed a workflow that uses a simple word2vec model that embeds SMILES strings and combined them with classical machine learning regressors to yield predictive models of astrochemical inventories. In this project, I worked with Haley Scolati, a graduate student at the University of Virginia, to extend the workflow to a new astronomical source, and a combination of new modeling techniques. First and foremost, this paper tackles Orion KL—a source that contrasts TMC-1 in almost every way; relatively warm, turbulent, and multiple velocity components.
In this project, we sought to automate the search for new possible molecules. The premise is simple: given an inventory of molecules, could we use machine learning to identify what comes next, and on a related note, predict how much there might be?
Status: Code and models are available on Github, and published in Ap. J. Letters.