Unsupervised molecule discovery in astrophysics
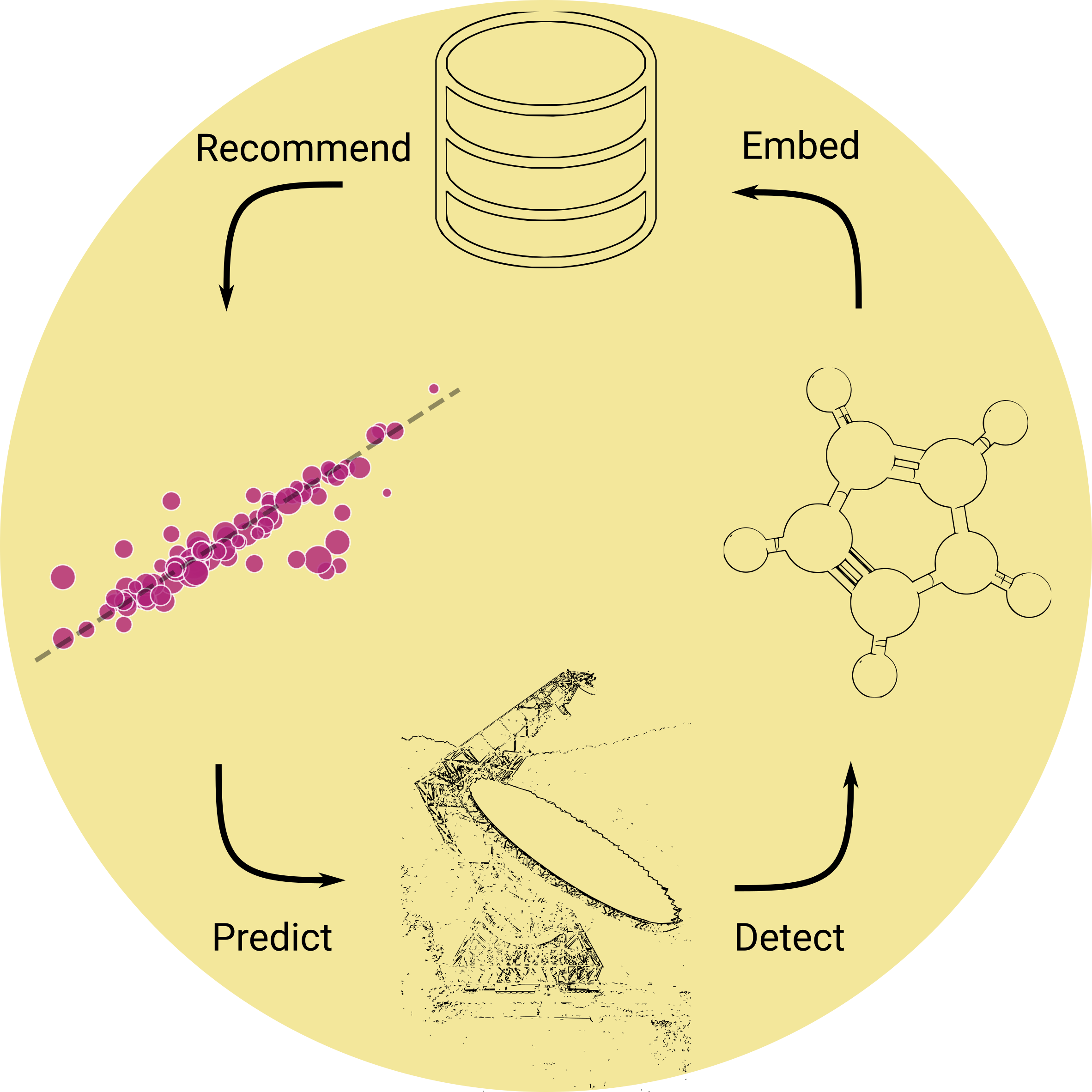
Every new molecule detected in space goes towards answering broader questions about chemical reactivity, the formation of biomolecules, and large scale processes like planet and star formation in the interstellar medium.
In more recent times, observational facilities like the Green Bank Telescope push the complexity of molecules we are able to detect. The typical astrochemistry consensus for measuring complexity is based on the number of atoms (i.e. > 6 atoms is a "complex molecule"). This definition of course does not take into account complexity as represented in structure and reactivity. As we get to larger molecules, the question of "what comes next?" becomes more and more difficult to answer: for simple linear chains like HCN, the motif is simple enough, but for molecules like the recently detected cyanonaphthalenes the number of isomers is considerably larger. Human intuition alone is not sufficient to cover all the possibilities.
In this project, we sought to automate the search for new possible molecules. The premise is simple: given an inventory of molecules, could we use machine learning to identify what comes next, and on a related note, predict how much there might be?
Status: Code and models are available on Github, and published in Ap. J. Letters.